ClashBot
Motivation & Inspiration
Modern autonomous systems increasingly rely on a combination of imitation learning and reinforcement learning to make decisions in complex environments. I became interested in this paradigm after seeing how systems like self-driving cars can learn from both human demonstrations and large-scale simulation.
A major inspiration was DeepMind’s work on AlphaStar, which demonstrated that combining imitation learning with reinforcement learning and league-based self-play could produce highly strategic behavior in a real-time game. What stood out most was their finding that training on human data first dramatically improves learning efficiency and stability.
I wanted to explore whether these ideas could be reproduced on a smaller scale in Clash Royale, a fast-paced, real-time strategy game with a large action space and strong reliance on human intuition. Unlike turn-based games, Clash Royale requires continuous decision-making under uncertainty, making it an interesting testbed for studying learned strategy.
Project Scope & Challenges
ClashBot is an end-to-end system that required building multiple components from scratch:
A pipeline to generate imitation learning data from raw gameplay videos
A computer vision system to extract structured game state and player actions
A representation of the game suitable for machine learning
A model capable of predicting actions from observed states
One of the biggest challenges was that no public dataset exists for this problem. This meant I needed to construct a dataset entirely from scratch, using noisy visual data as the only source of ground truth. Ensuring accuracy and consistency across this pipeline became a central focus of the project.
Game Background
In Clash Royale, players deploy troops and spells to destroy their opponent’s towers while defending their own. Each action costs elixir, a resource that regenerates over time, forcing players to balance offense, defense, and resource management.
Strong play requires:
Understanding interactions between different troop types
Managing elixir efficiently
Timing and positioning actions precisely
Anticipating opponent behavior
These factors make the decision space both large and highly contextual, which makes it difficult to solve using deterministic or rule-based approaches.
Imitation Learning Pipeline
To train a model, I needed to construct a dataset of state-action pairs from gameplay videos.
State included:
Troop positions and identities
Cards in hand
Elixir values
Actions included:
Which card was played
Where it was placed
Instances where no action was taken (NOOP)
I sourced gameplay footage from a large YouTube dataset and downloaded videos using yt-dlp. From there, the core challenge became extracting structured information from raw pixels.
Computer Vision System
Elixir Detection
Elixir was extracted by masking the image to isolate purple pixels and measuring the fill level of the bar using a horizontal scan. This provided a fast and reliable estimate of available resources at each frame.
Number Recognition
To extract values such as tower health and match timers, I initially experimented with OCR, but found it too slow for large-scale processing.
Instead, I built a custom system:
Detect digit regions using connected components
Normalize them into fixed-size images
Compare against precomputed template masks for digits 0–9
This approach allowed for near-instant classification and scaled efficiently to large datasets.
Card Recognition
With over 100 possible cards, training a full object detection model would have required extensive labeling. Instead, I designed a lightweight alternative based on color matching.
Extract a 32×32 region from each card
Divide into a 4×4 grid
Compare average colors to official card images
This method was extremely fast and surprisingly robust, even for visually similar cards, and eliminated the need for large labeled datasets.
Card Cycle Reconstruction
A key challenge was that cards appear greyed out when they cannot be played, making them difficult to classify visually.
To address this, I leveraged the deterministic nature of Clash Royale’s card cycle:
Each player has a deck of 8 cards and a hand of 4
Played cards cycle back to the bottom of the deck
By tracking card placements over time, I reconstructed the full hand state at every moment.
To handle noisy detections (e.g., missed frames or duplicate events), I implemented a consistency-based optimization:
Assign a score based on how logically consistent the reconstructed sequence is
Iteratively adjust detected placements to maximize this score
This significantly improved reliability across all processed matches.
Troop Detection & Tracking
Initially, I considered training a model to classify all troop types, but this proved impractical due to the large number of classes and frequent occlusion.
Instead, I focused on detecting health bars, which are more stable visual features.
Trained a YOLO model on ~200 labeled images to detect health bars (~98% accuracy)
Used deployment indicators to detect where troops were spawned
Tracked troop positions over time using tracking techniques developed in my AutoScout project
This provided a robust way to estimate troop positions without needing to classify each unit directly.
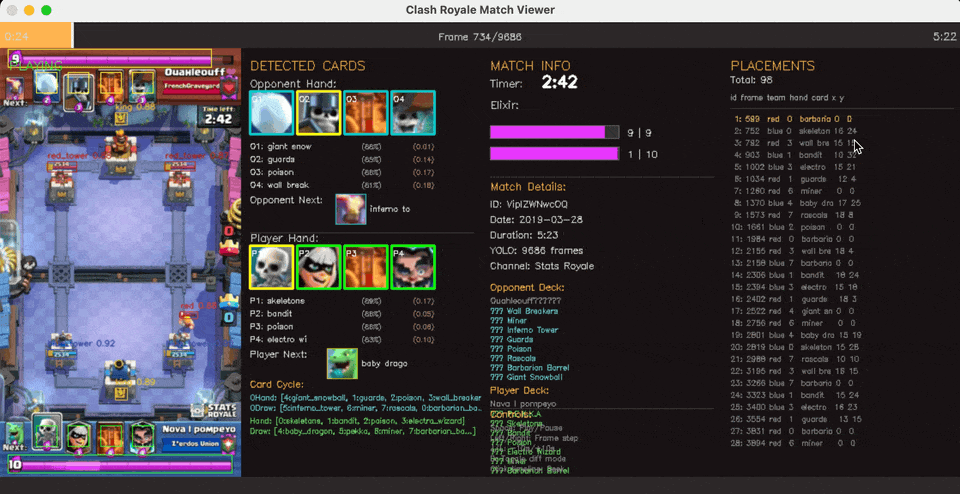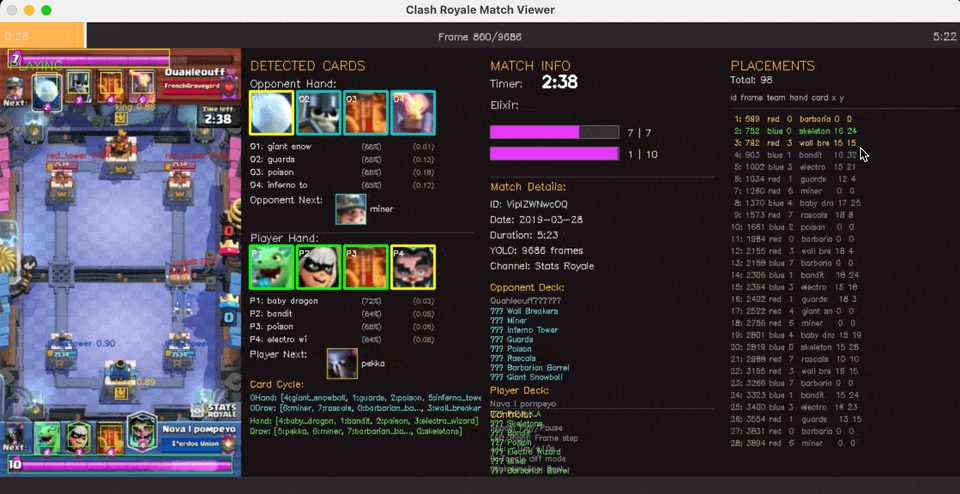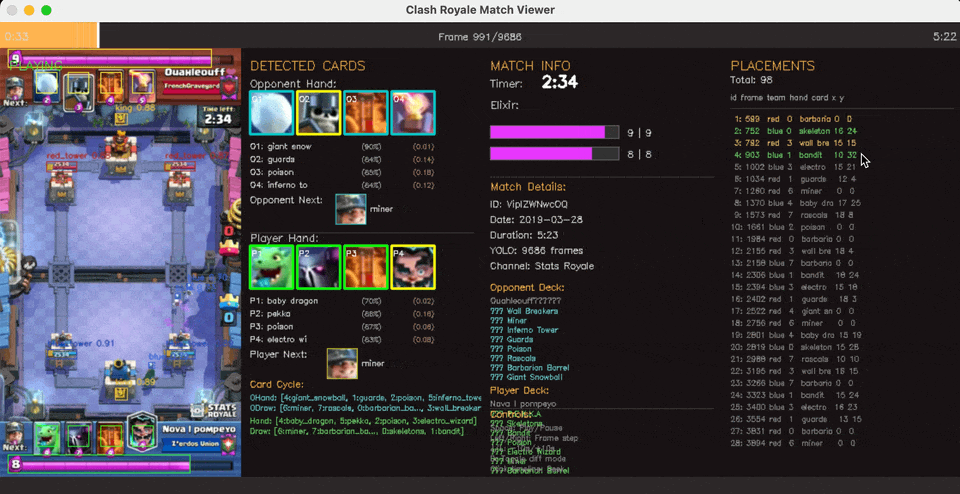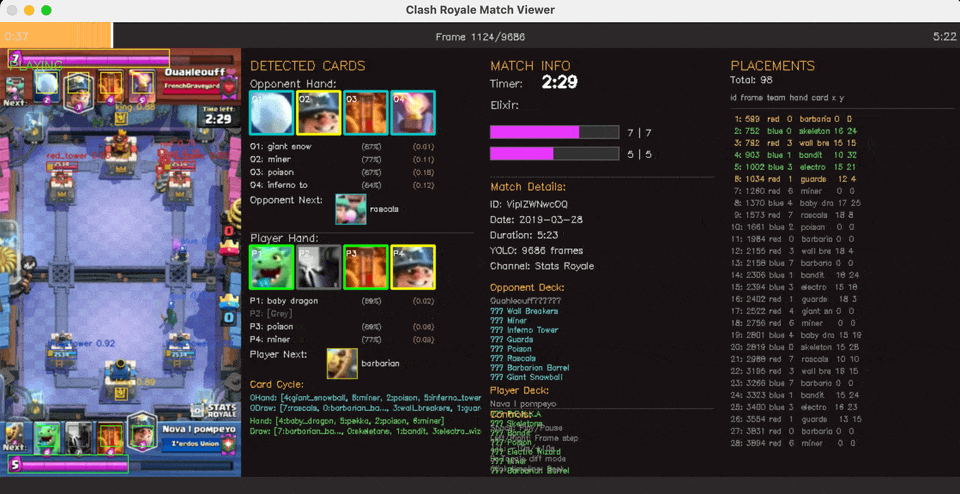
State Action pair extraction
Gameplay on the right, State action pairs being extracted on the left, with [ID, frame_number, player, hand_slot, card, x, y]
First Imitation Learning Model
I designed an initial model inspired by AlphaStar, but simplified for this setting.
Inputs:
Up to 16 friendly and 16 enemy troops, sorted by position
Encoded card hand
Elixir value
Architecture:
Two separate prediction heads:
Card selection (including NOOP)
Placement position
The model was trained on a dataset with a balanced mix of action and no-action examples.
Results:
The model learned to place units in reasonable positions
However, its strategic decisions were still inconsistent
The primary limitation appeared to be noise in the training data, particularly in troop tracking.
Key Insight: Simulation for Data Correction
A major realization came from drawing parallels to robotics, where systems often combine multiple sources of information to improve accuracy.
In robotics, techniques like sensor fusion combine noisy measurements (e.g., wheel odometry) with external references (e.g., visual markers) to produce more accurate estimates.
I plan to apply a similar idea here:
Build an internal simulation of the game
Compare simulated troop positions with those observed from vision
Use discrepancies to identify and correct errors in the dataset
This approach would allow the system to refine its own training data, improving quality without requiring manual labeling.